
A not uncommon question about Prometheus is why the Alertmanager is a separate binary. Let's look at that.
The split of responsibilities is that Prometheus determines what is wrong and sends alerts. The Alertmanager takes these alerts, and converts them to notifications via email, PagerDuty, Slack etc.
A Merged World
Let's say the Alertmanager were to be merged with Prometheus. If you only had one Prometheus server, the semantics would be the same. What happens if you have more than one Prometheus server though?
The first step in scaling Prometheus is by splitting multiple vertical slices, one for infrastructure and another for applications say. An event such as a rack failure could result in notifications from each Prometheus.
The standard solution to making Prometheus fault-tolerant is to run two identical Prometheus servers that are both active at the same time. With a combined binary, this would mean you get all the notifications twice.
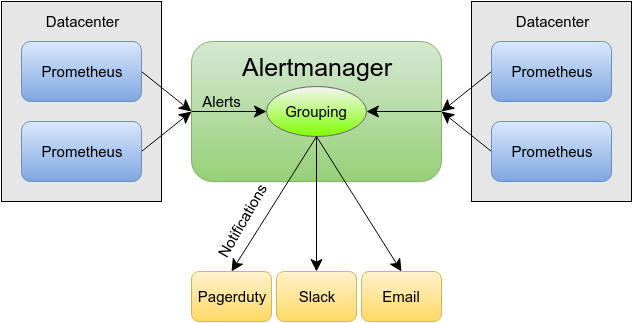
If you have multiple datacenters you'd have at least one Prometheus each. An application problem that arises in multiple datacenters would mean one notification per datacenter. That could be tens of notifications for a single event!
Grouping is a Killer Feature
Limiting the number of notifications you get per event is an important aspect of preventing spammy notifications and thus keeping pager fatigue at bay. With a single Alertmanager and the power of Prometheus labels, alerts can be grouped by datacenter, application or on whatever other axis makes sense to you. An event that such as a rack failure that causes alerts in multiple Prometheus servers can be grouped back into one notification in the Alertmanager.
Inhibits are another feature that only come into their own when there's a common Alertmanager for your organisation. Say a datacenter has fallen over and is no longer receiving any user traffic. One Prometheus can send an alert indicating this is the case, and an inhibit in the Alertmanager can prevent notifications from other Prometheus servers such as low traffic warnings from being sent out.
Prometheus values reliability over consistency, which is why we avoid clustering as it's notoriously difficult to get correct. We want to ensure that you can scale and manage your monitoring setup in a sane fashion that doesn't burn out your staff. A centralised Alertmanager that is separate from Prometheus allows for more sophisticated notification strategies that continue to work as the number of Prometheus servers grows.



No comments.