
When starting out it's easy to think that you need Docker, Kubernetes, Microservices, Continuous Deployment and all the other trending topics on Hacker News/Reddit/Lobsters. What do you really need?
It's easy to get overwhelmed by all the great posts and presentations by companies sharing how they run their infrastructure, and how they've evolved it to be more efficient over time. These tend to implicitly assume that you've spent years laying the foundations that'd allow you to take full advantage of these technologies, so jumping right in may leave you lacking fundamentals.
A good way to go is ensure is that your infrastructure has the basics, and then grow that over time. You need to know:
- How to recreate your system
- How to safely change your system
- When something has gone wrong
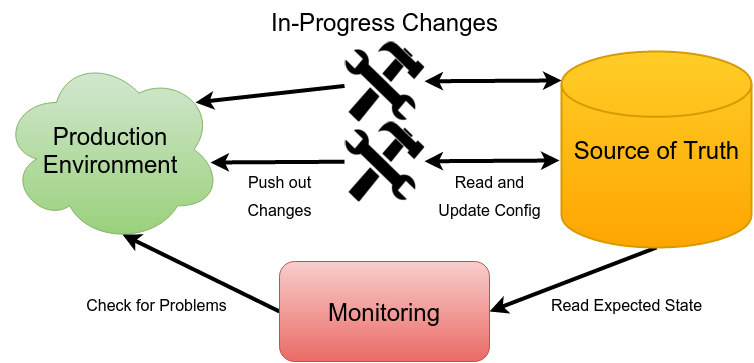
Basic Infrastructure Interactions
How to recreate your system
The first fundamental is also the simplest. You should, without having to refer to the running system, be able to get a production environment up and running from scratch.
Now you might jump to thinking about a tool like Ansible, Puppet or Chef; but I didn't say you needed a configuration management tool. All you need is a way to express what you think your production environment should look like, preferably with some form of versioning. This is your source of truth.
This could start out as wiki page. Over time this should be moved towards a more sophisticated tool, particularly as you get too many machines to do things by hand.
Using tooling is an efficiency improvement, that is to say it is a means rather than an end. Of course it rarely hurts to have your source of truth in source control backed by a tool from day one.
Keep in mind that while tooling is great there'll always be tasks that are rarely performed, such as datacenter turnups, that'll tend to live in documentation rather than code. As our goal isn't to blindly automate everything, that's okay.
How to safely change your system
It's all well and good to have your expected state of the world written down, however your production environment is not set in stone. You need to be able to mutate production, and keep your source of truth in sync.
New releases, new machines, new clusters, machine failure, cluster turndowns, security updates and configuration changes must all be allowed for. Furthermore, tens to hundreds of these changes could be ongoing simultaneously and you can't decide when machine failure happens!
When you're small the simplest approach is the best. If your company only has a handful of people in a room, it's easy to shout out "I'm going to change production now, everyone else hold off", make your change and update the source of truth.
As anyone who has run into the GIL in Python can tell you, one big lock has scaling challenges. As you grow to tens of machines, services, and people more granular locking and approaches that don't require synchronous communication between everyone are desirable. What works well is to set ground rules, so that everyone knows where they stand and how to act.
One such set of rules might be that it must always be safe to roll out whatever the source of truth says, in the face of any other changes to the system such as machine failure and binary releases. Releasing new binaries will have a predictable sequence of steps, and may involve granular locking to ensure they're aren't two concurrent releases of the same binary. It's generally wise to set a rollback policy, such as that it must always be safe to go back N releases and M days.
This does imply that you can't depend on releasing two binaries in lockstep. Such a rollout strategy tends to be fragile, and can almost always be broken into a sequence of smaller changes that can be be independently and safely rolled out.
In combination, these two points are the essence of Configuration and Change Management. Having a source of truth and safe ways to change it are essential to managing beyond a single machine.
When something has gone wrong
Those who are regular readers of this blog may be surprised that it's only in the final section that I bring up monitoring. The reason is that I consider it more urgent to have your house in order configuration wise. There's no point in you resolving an alert only to discover that your fix didn't stick. Or to get tangled in debugging as you can't determine what happened to a machine, as it's been manually managed without a record of changes. It's also kinda tricky to alert on problems if you don't know what services are meant to exist, and on which machines.
To start with, have an external blackbox end-to-end test. For example if you have a CRUD API, you might have a script that runs once a minute that creates, reads and deletes a record in the same way an end-user would and alerts if there's five failures in a row. This test should be kept basic, and treated as a smoke test. The goal of end-to-end blackbox monitoring is to tell you when things are really badly broken. Attempting to test every feature will lead to false positives, and ultimately pager fatigue. This should catch the majority of your problems initially, giving you time to add more in-depth monitoring.
Beyond the basics
As you evolve your systems, know what's meant to be the configuration, how to safely change it and when things go wrong. Starting out it could just be a wiki page, verbal locking and a HTTP 200 check. Once these foundations are in place, maintain them as you evolve your systems. This will give you confidence in evolving your infrastructure with higher velocity and fewer outages.



No comments.